Machine learning
Regression
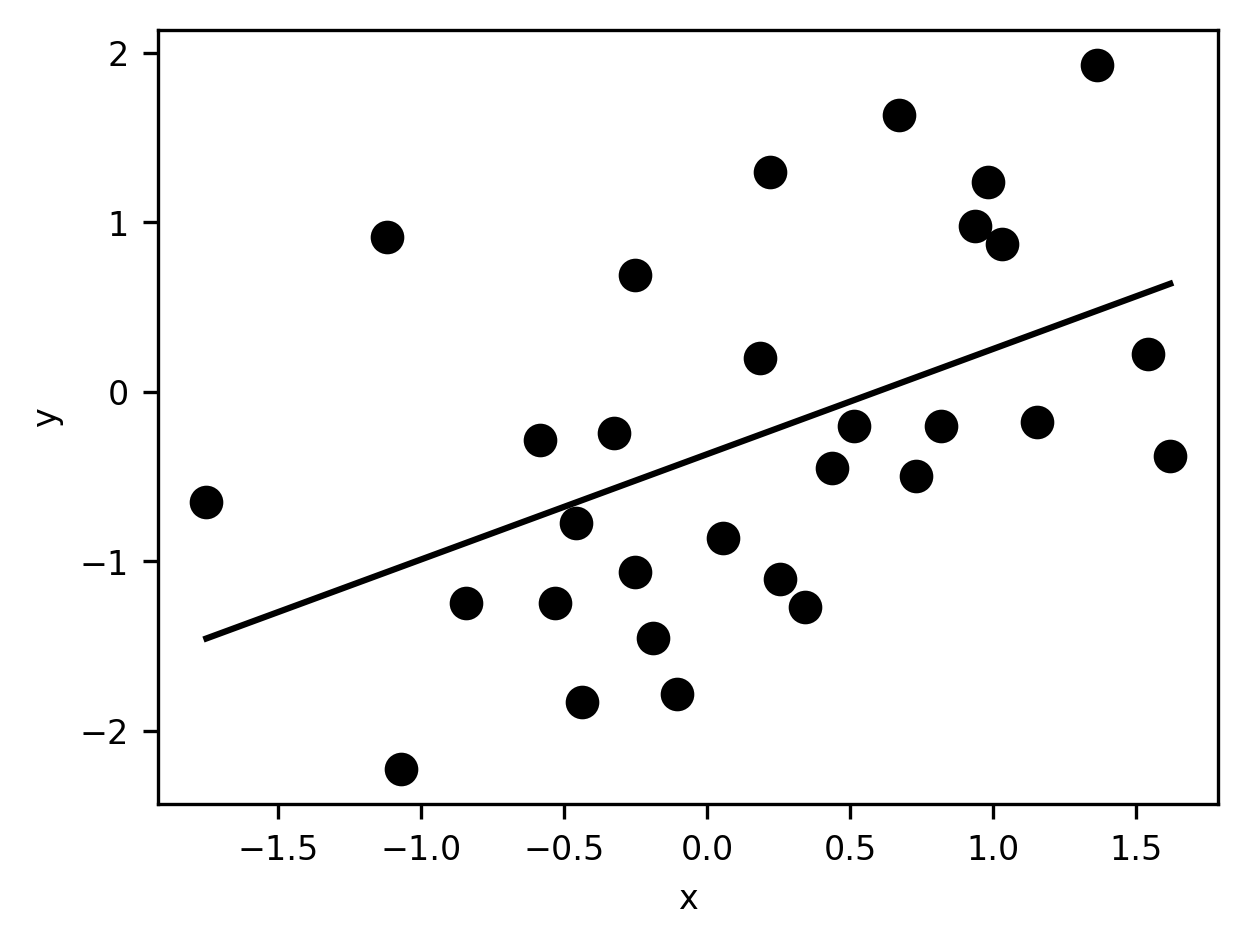
Regression
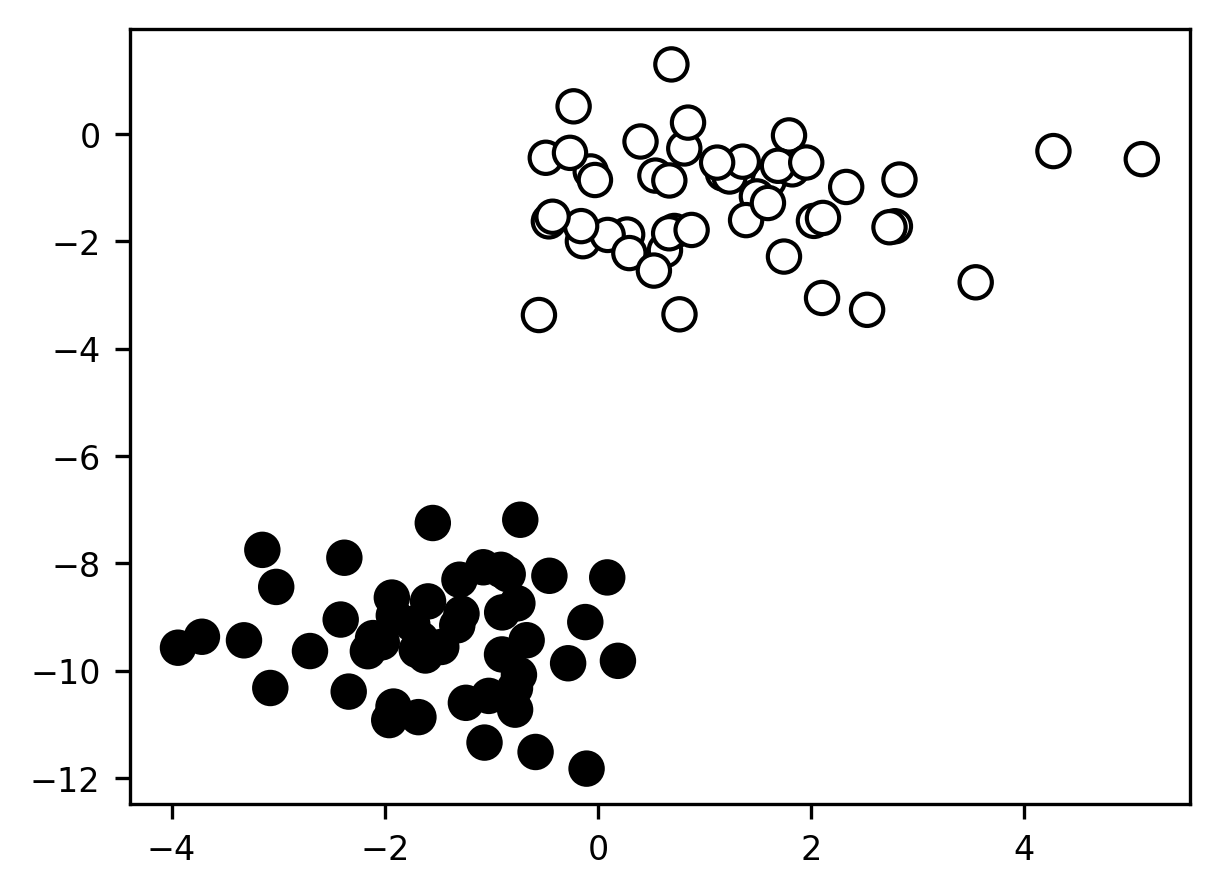
Classification
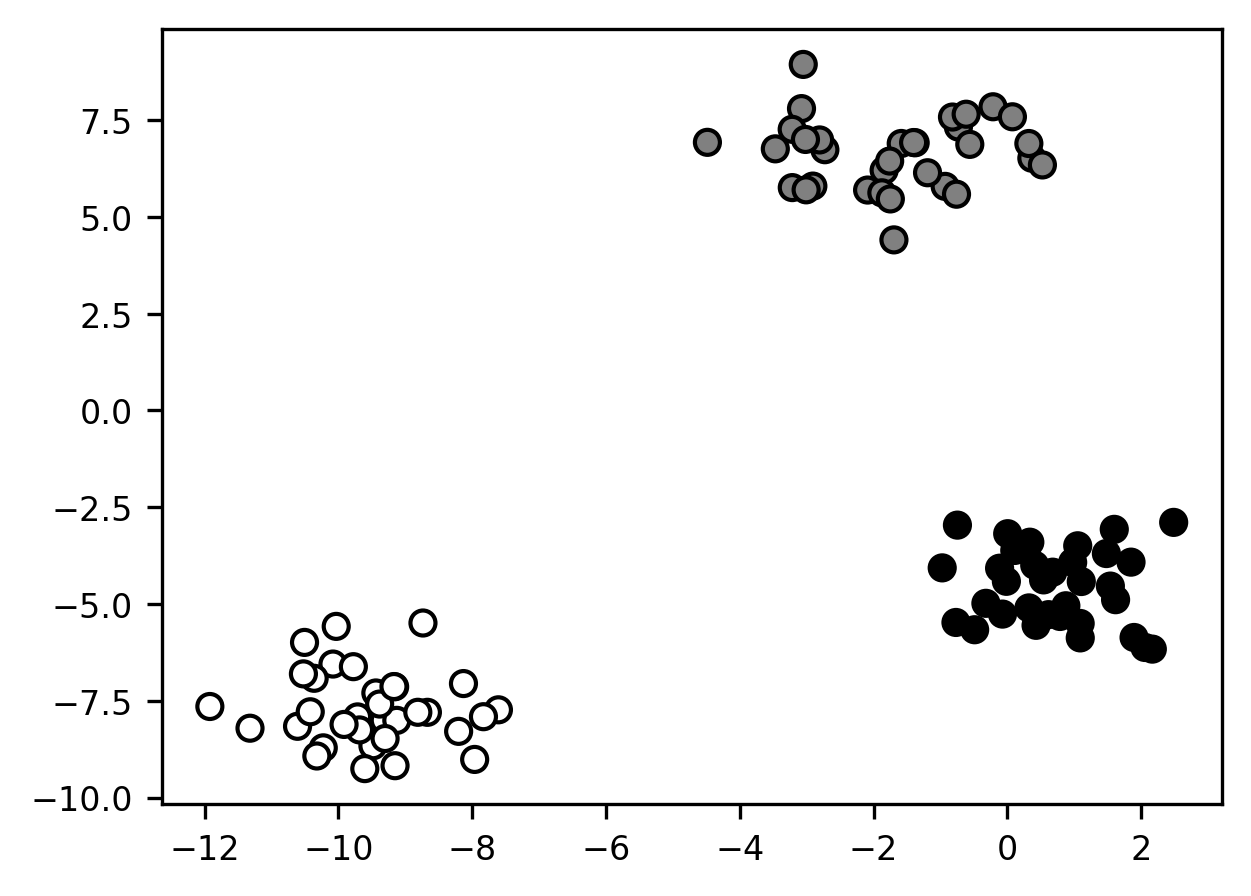
Clustering
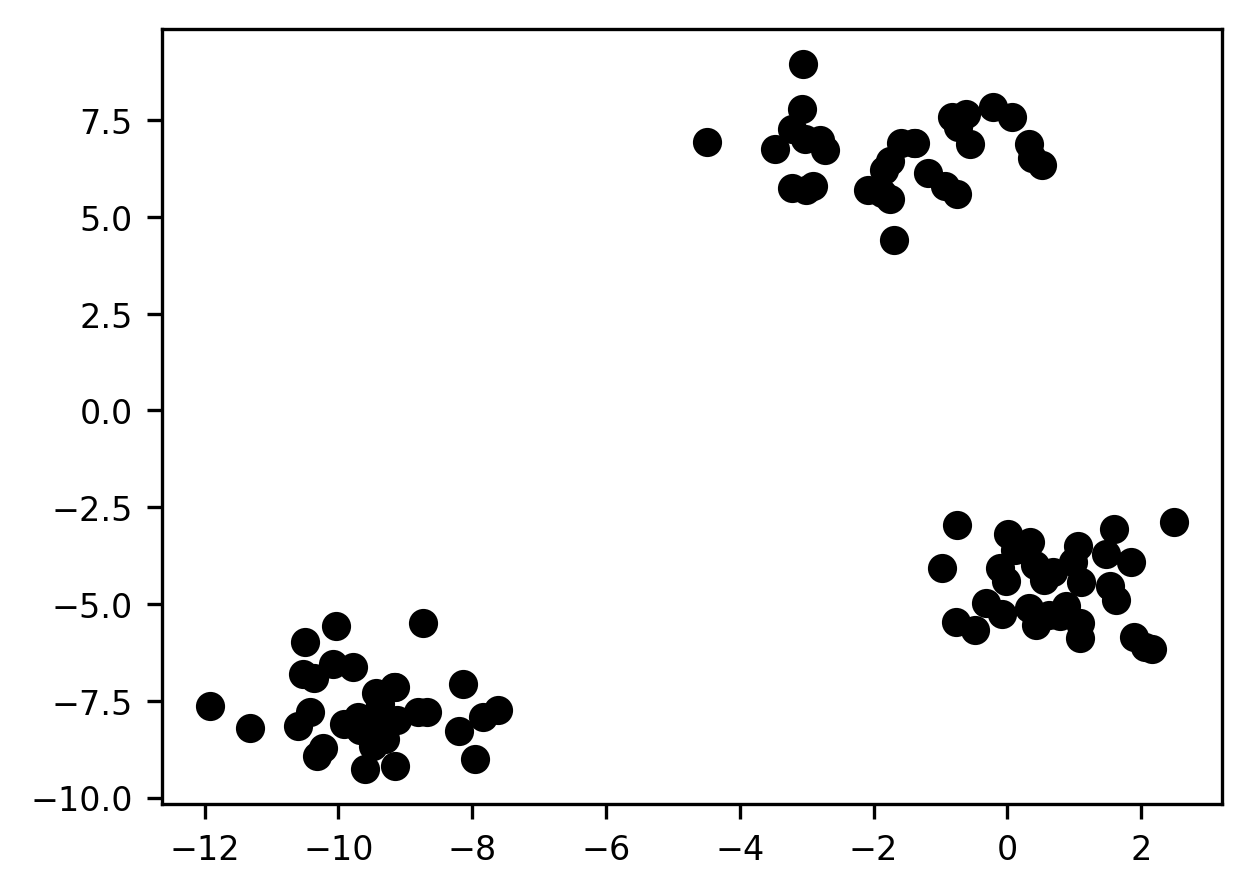
Clustering
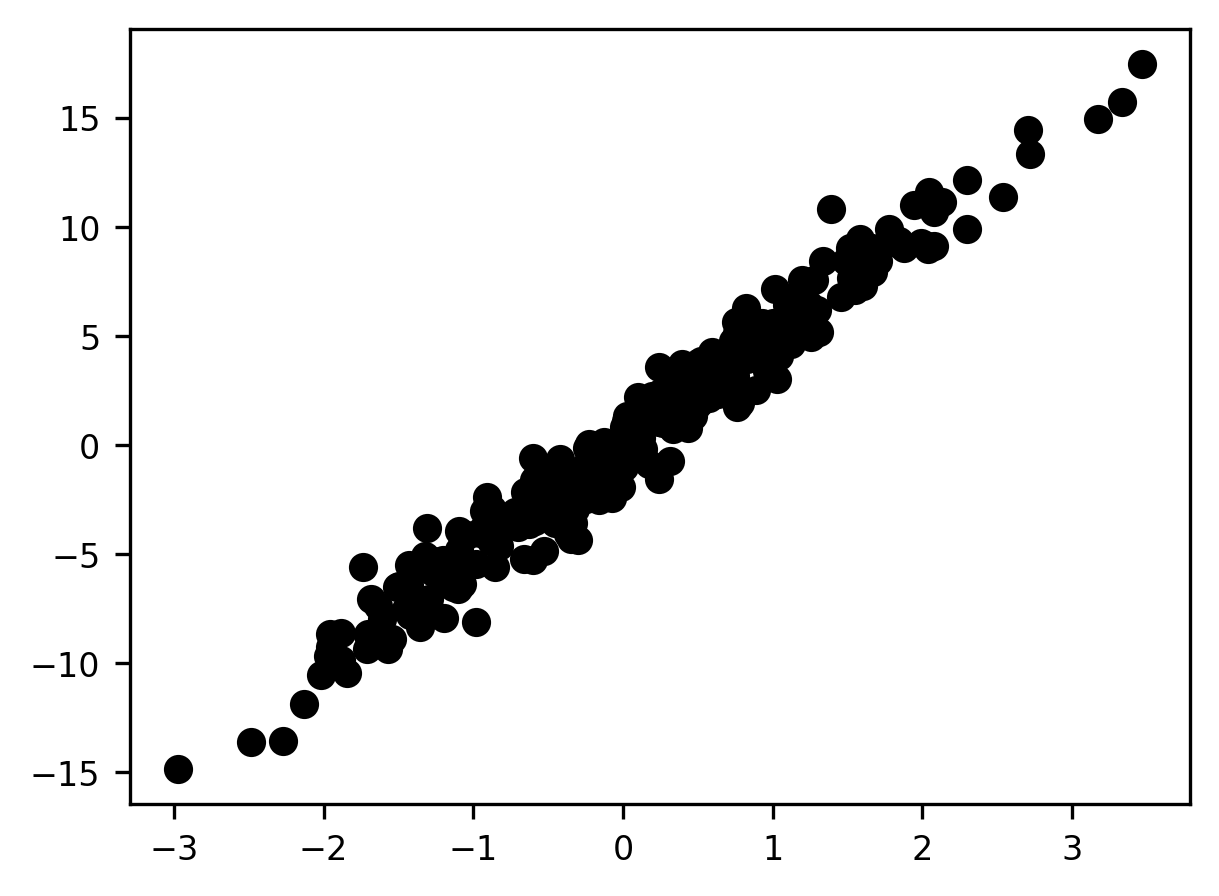
Dimensionality reduction
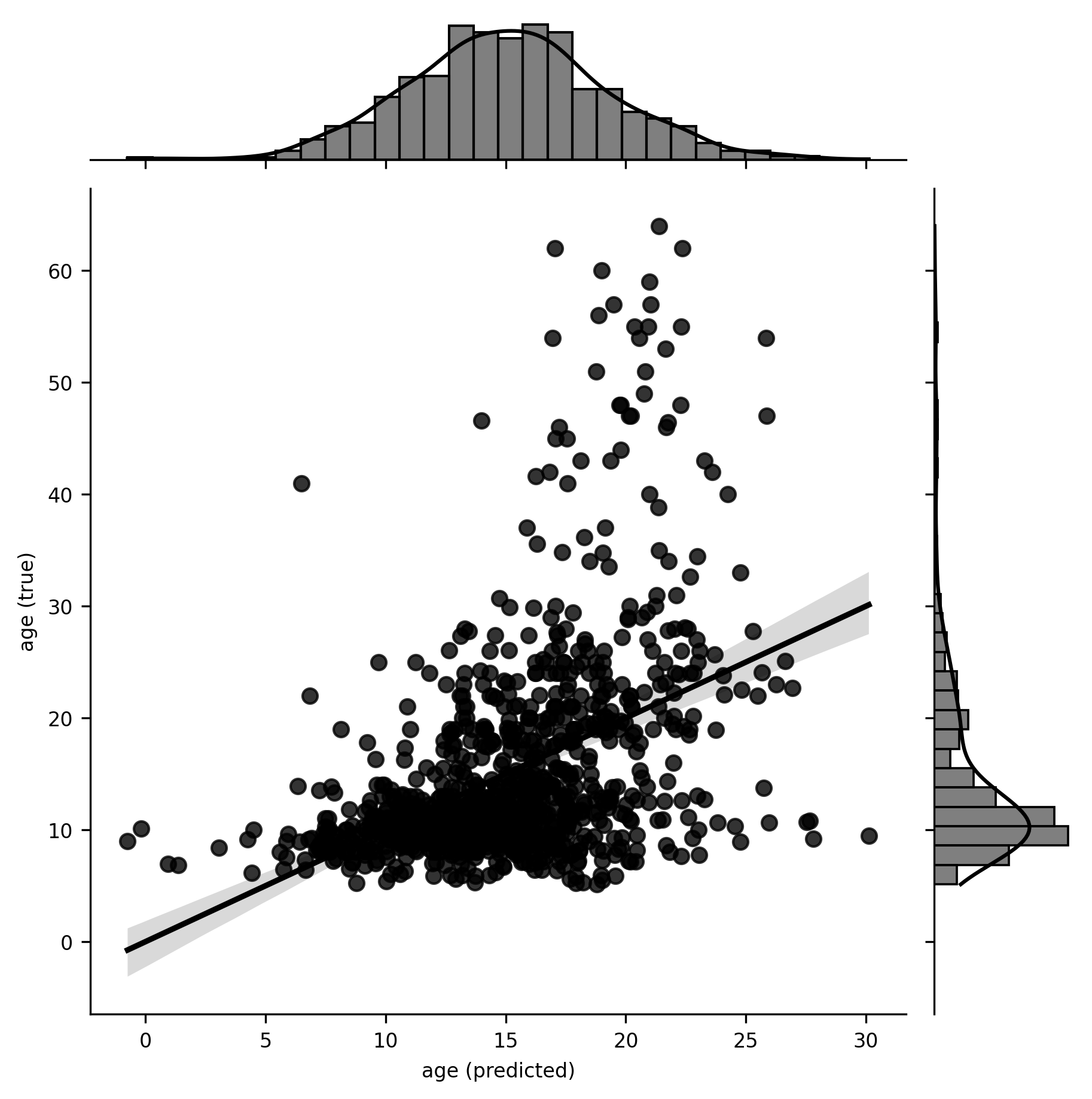
Quantifying performance

Quantifying performance
\(R^2 = 1 - \frac{SS_{res}}{SS_{tot}} = 1 - \frac{\sum{(y - \hat{y})^2}}{\sum{(y - \bar{y})^2}}\)
\(R^2 = 0.2\)
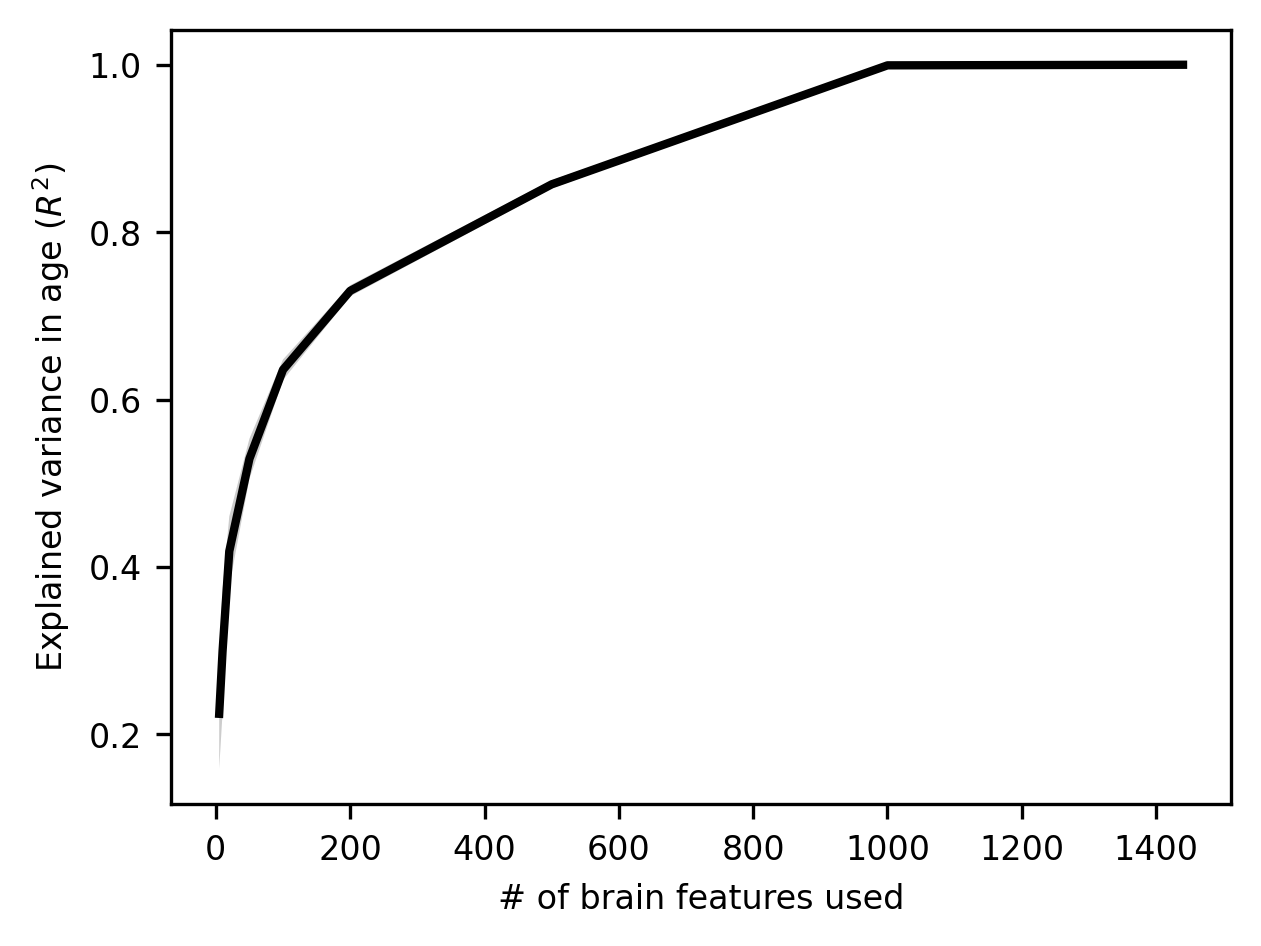
Quantifying performance
Overfitting
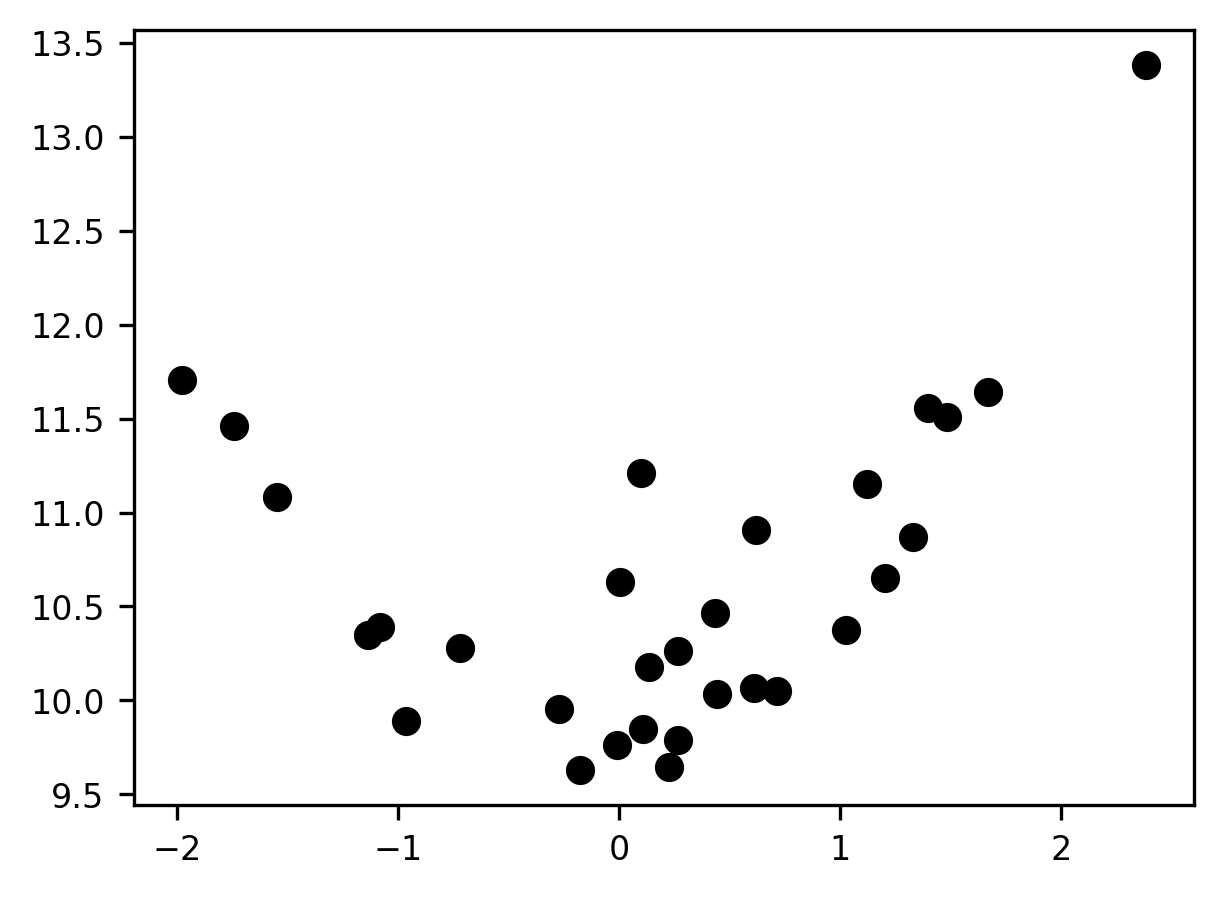
Overfitting
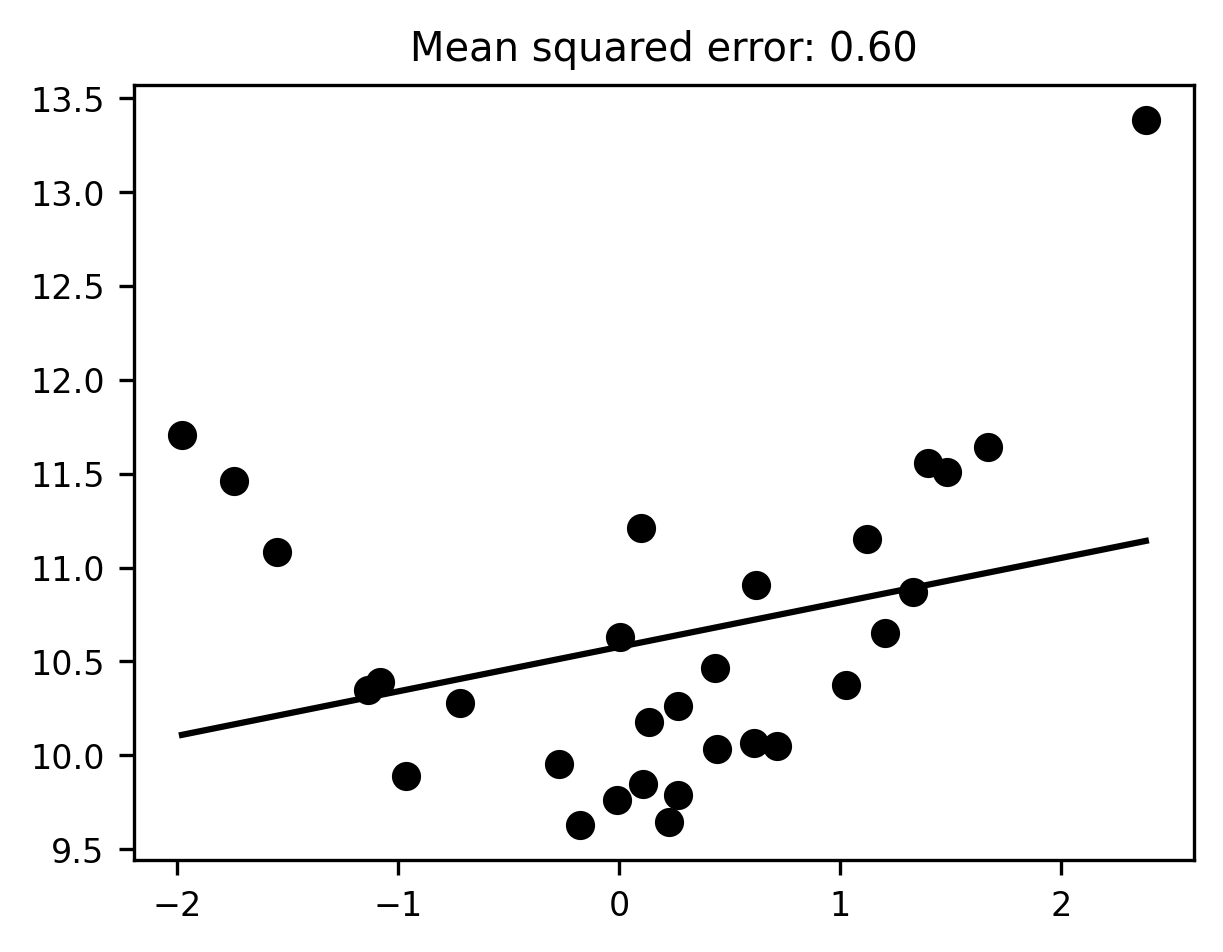
Overfitting
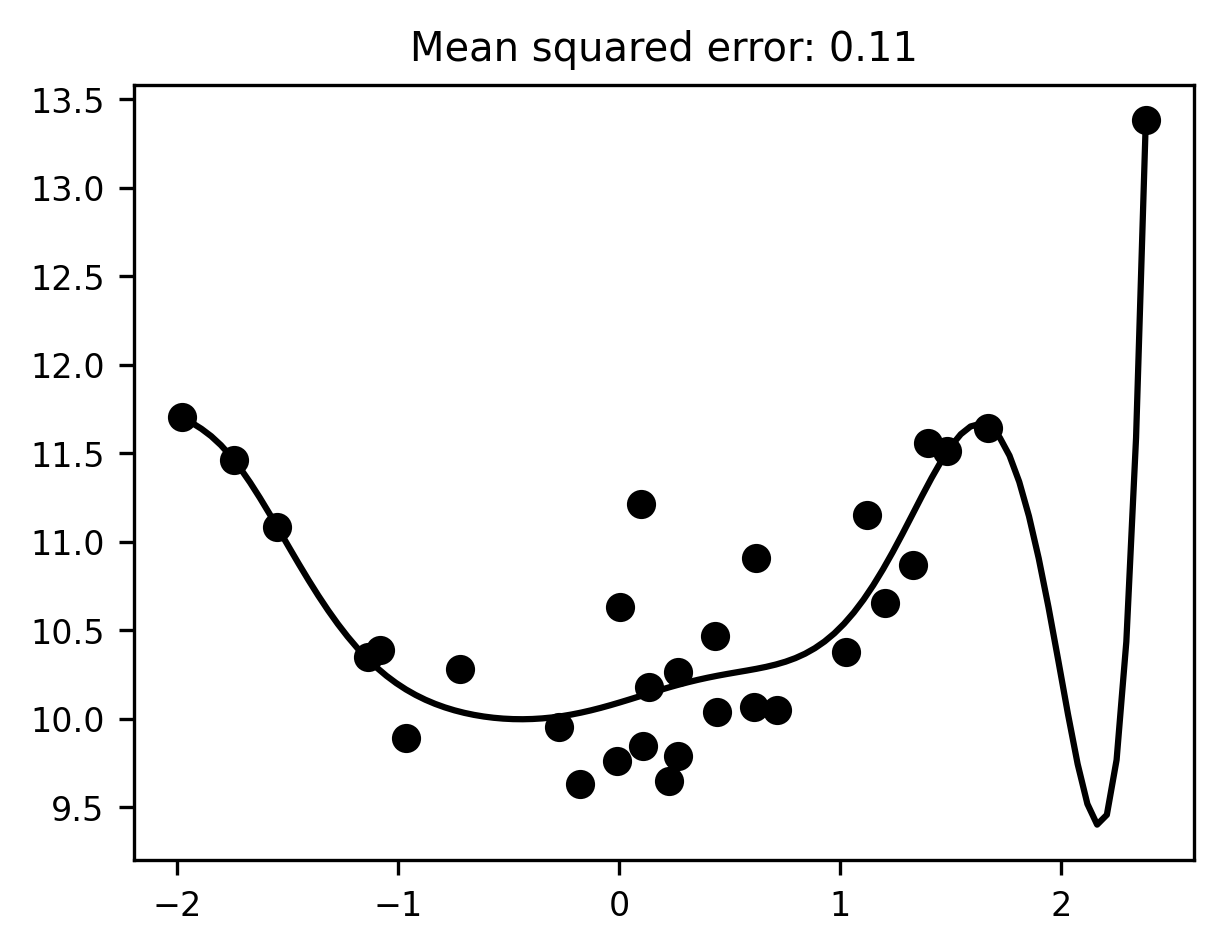
Overfitting
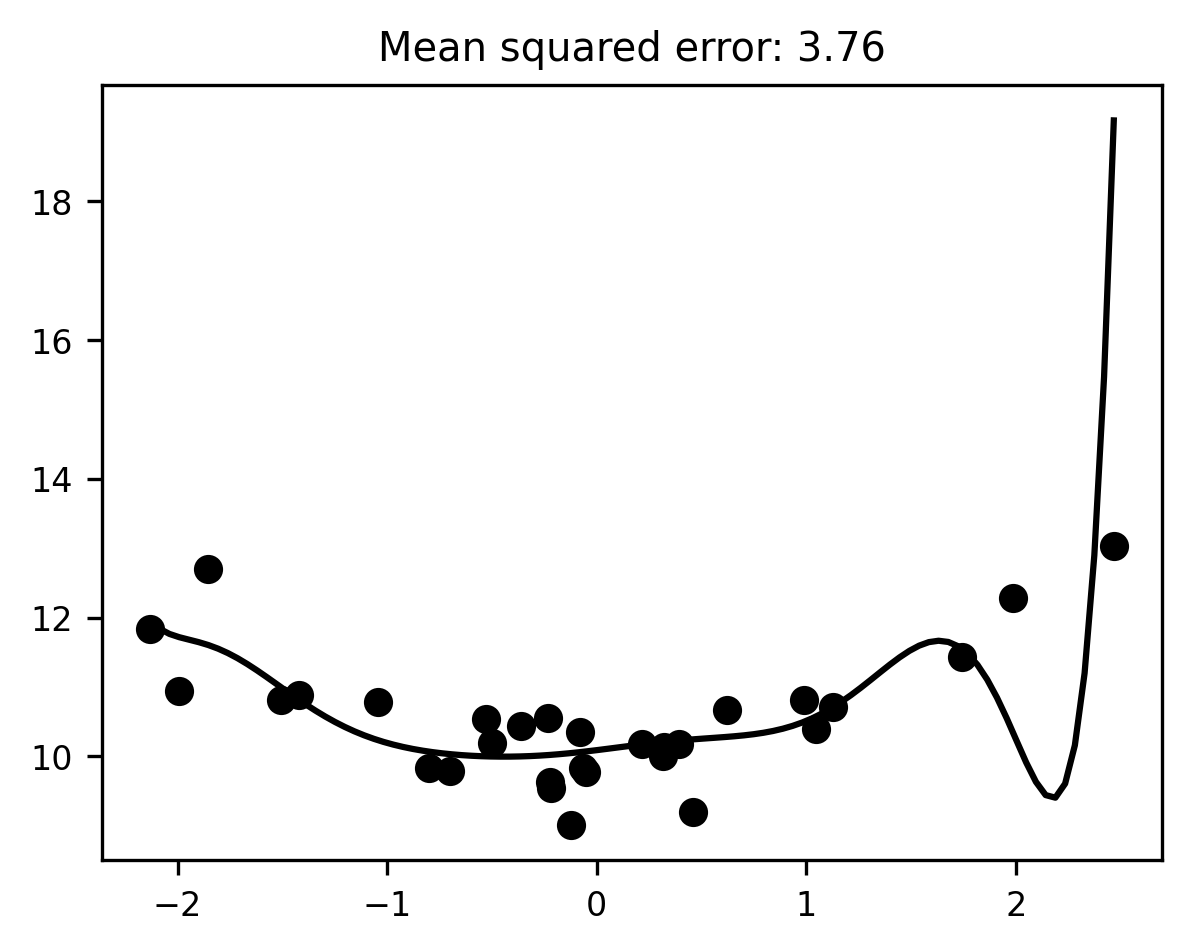
Overfitting
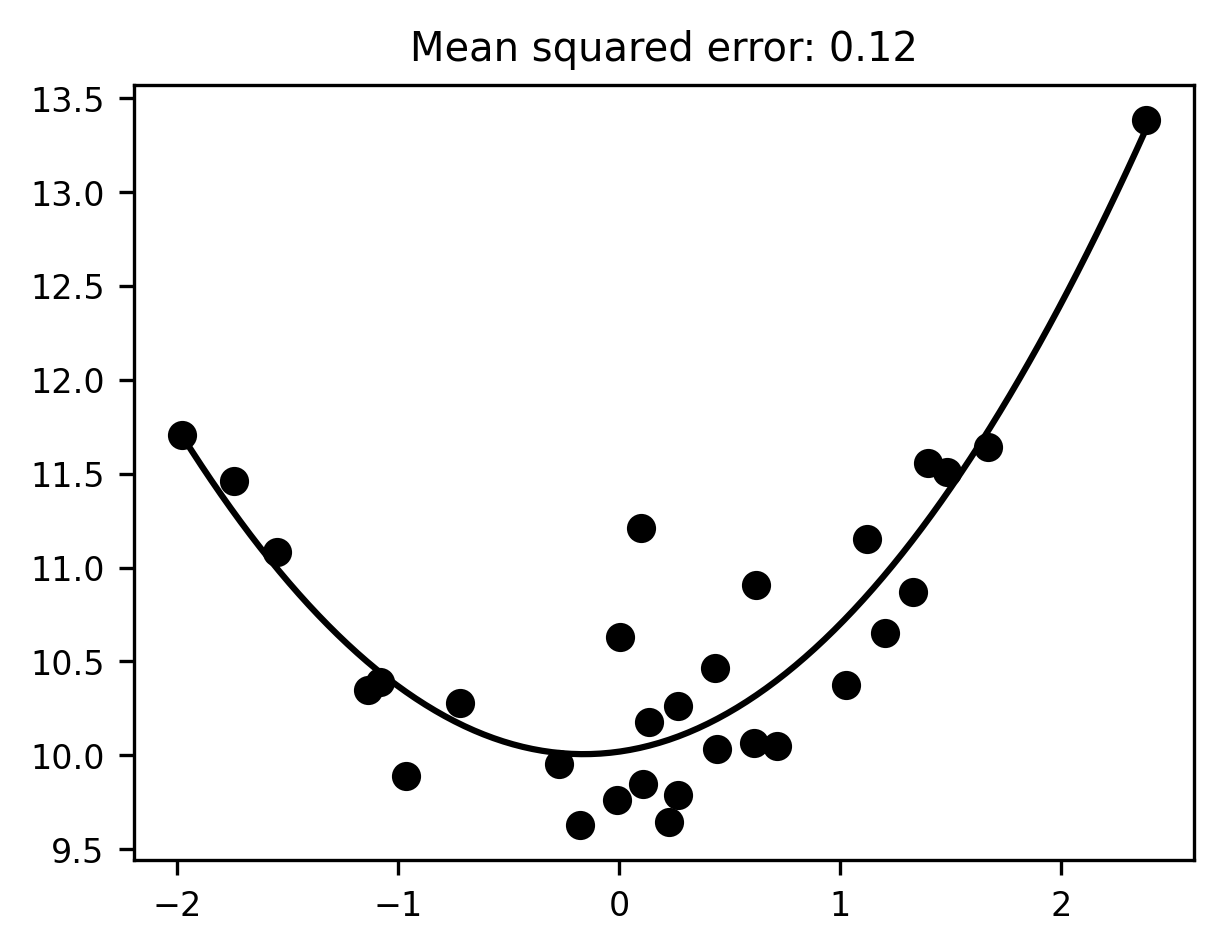
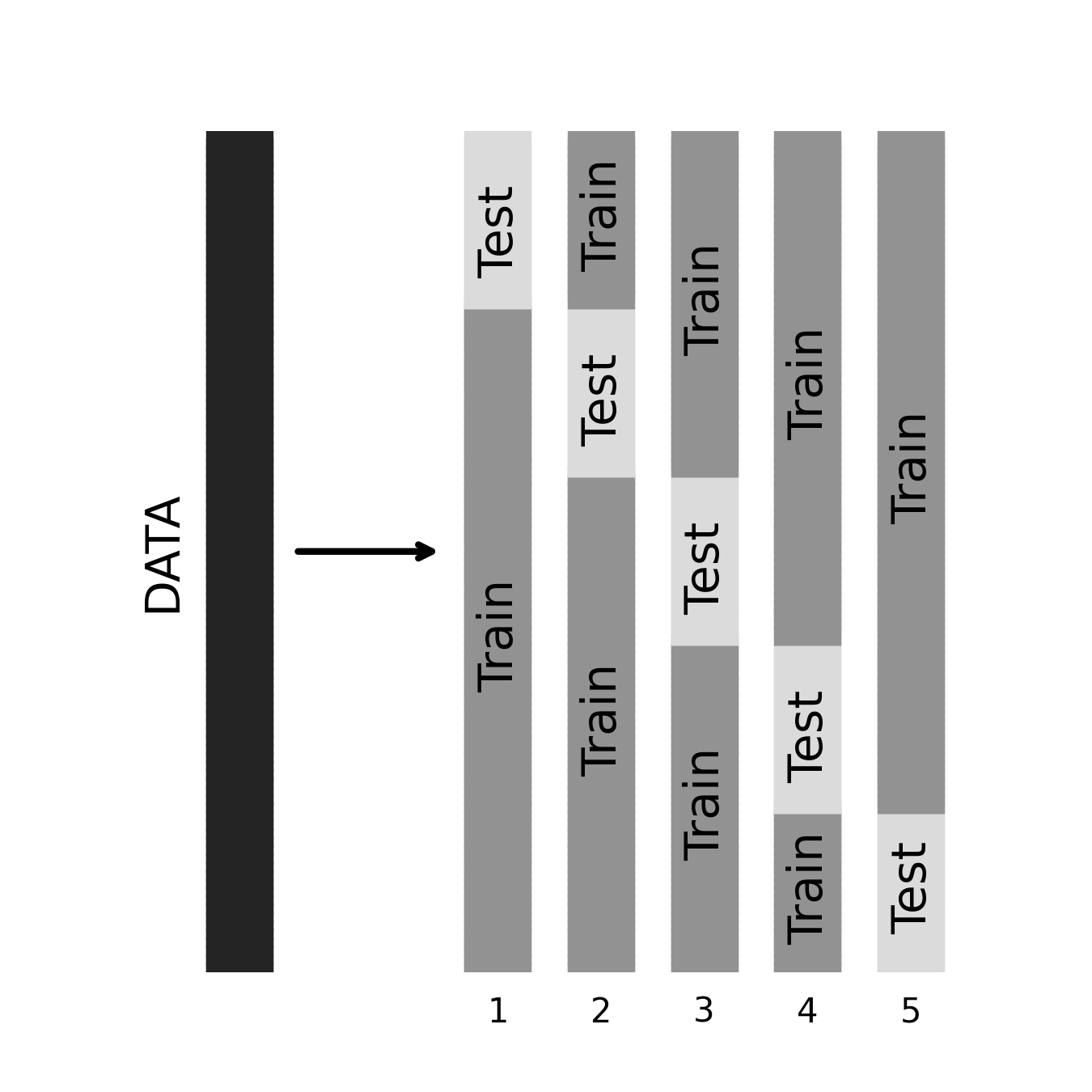
Cross-validation
The bias variance tradeoff
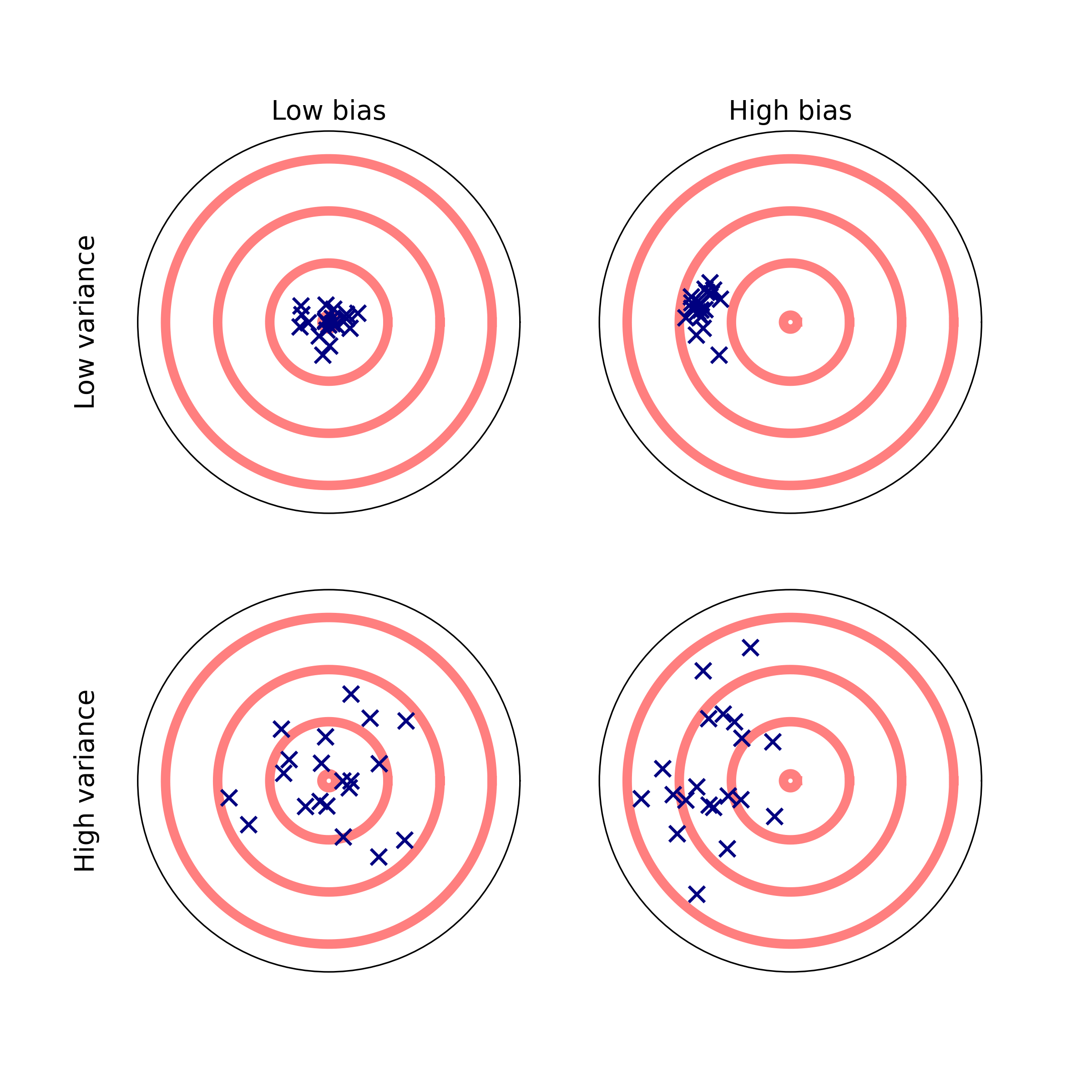
But how do we know how much bias?
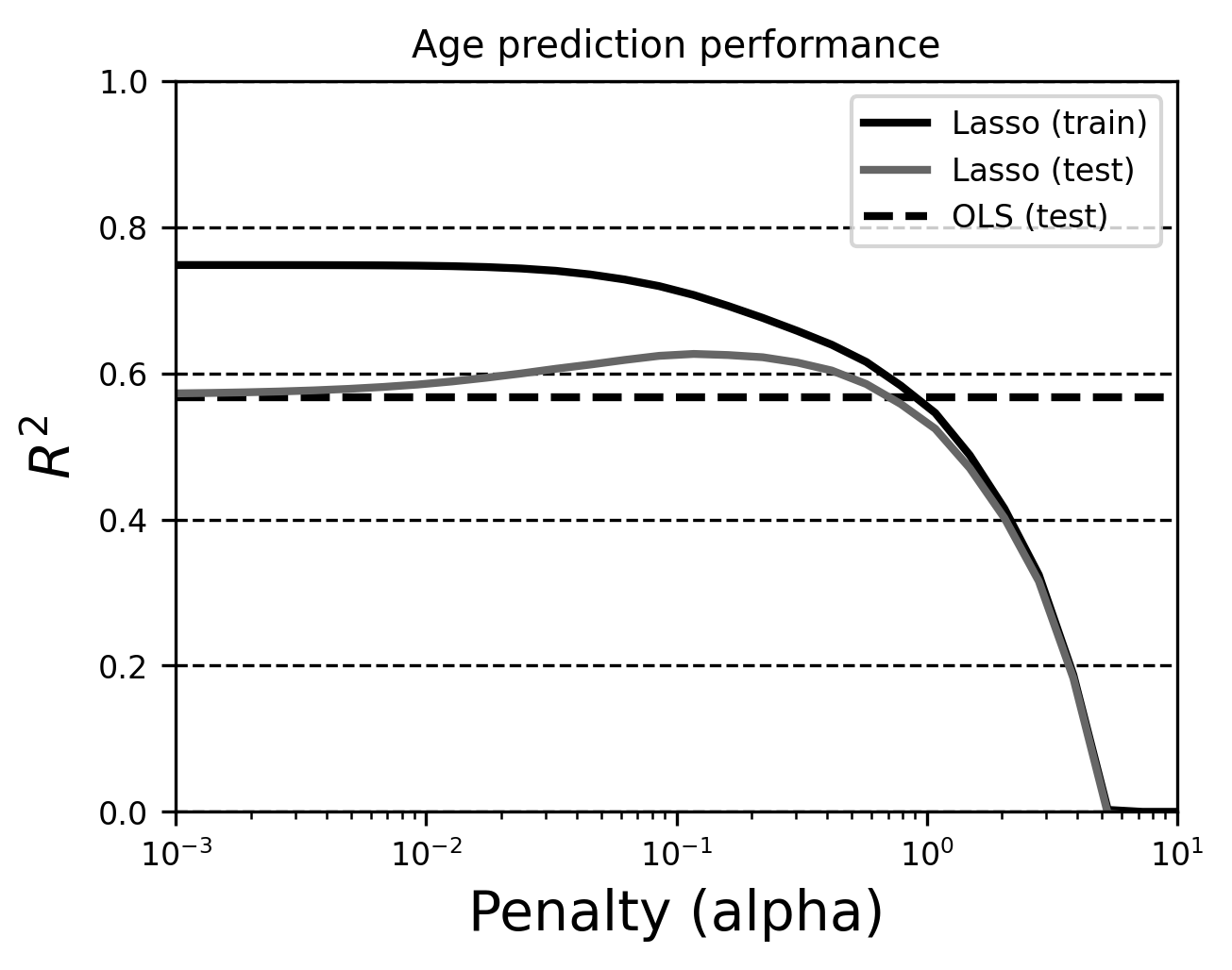
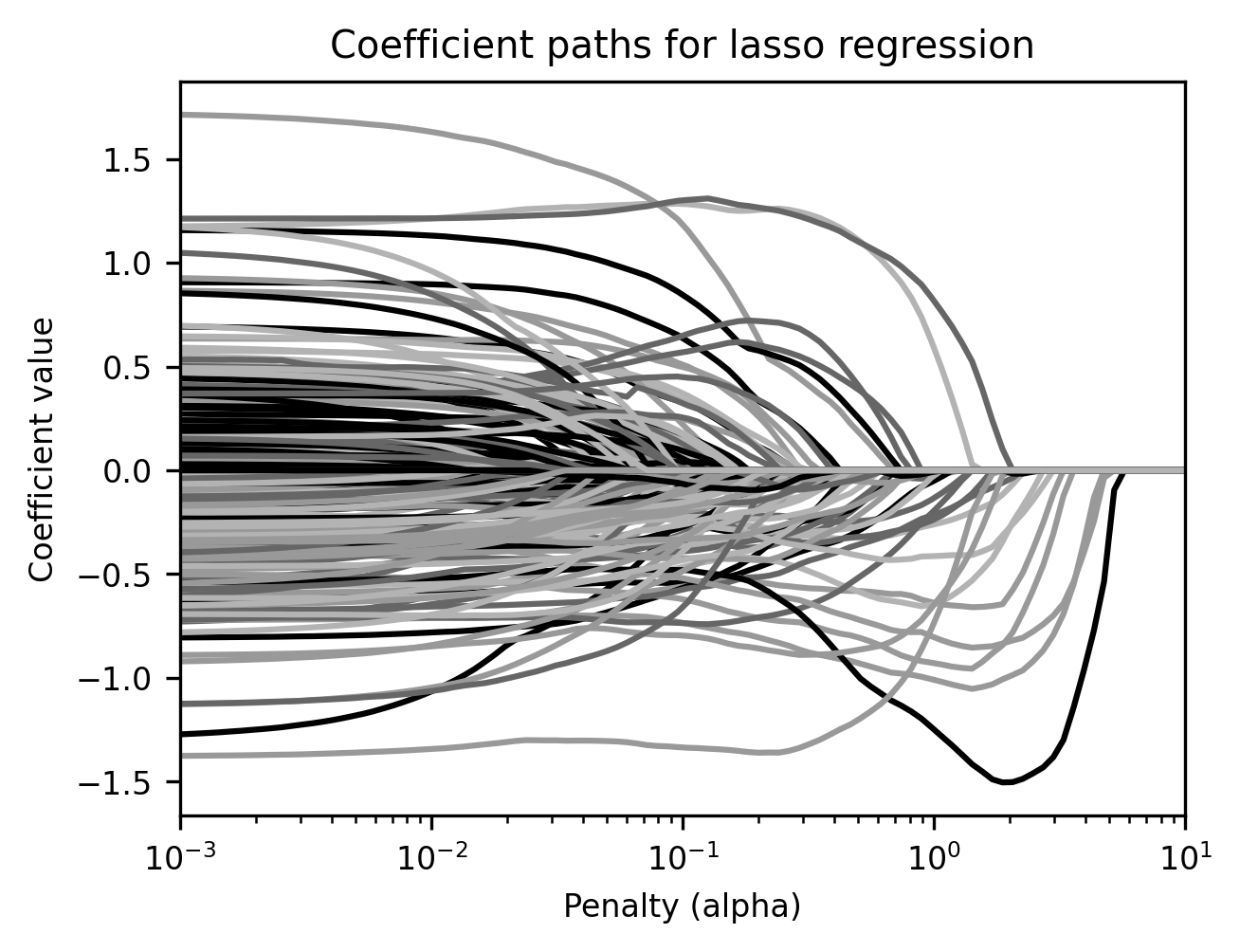
Lasso
Cross-validation for model selection
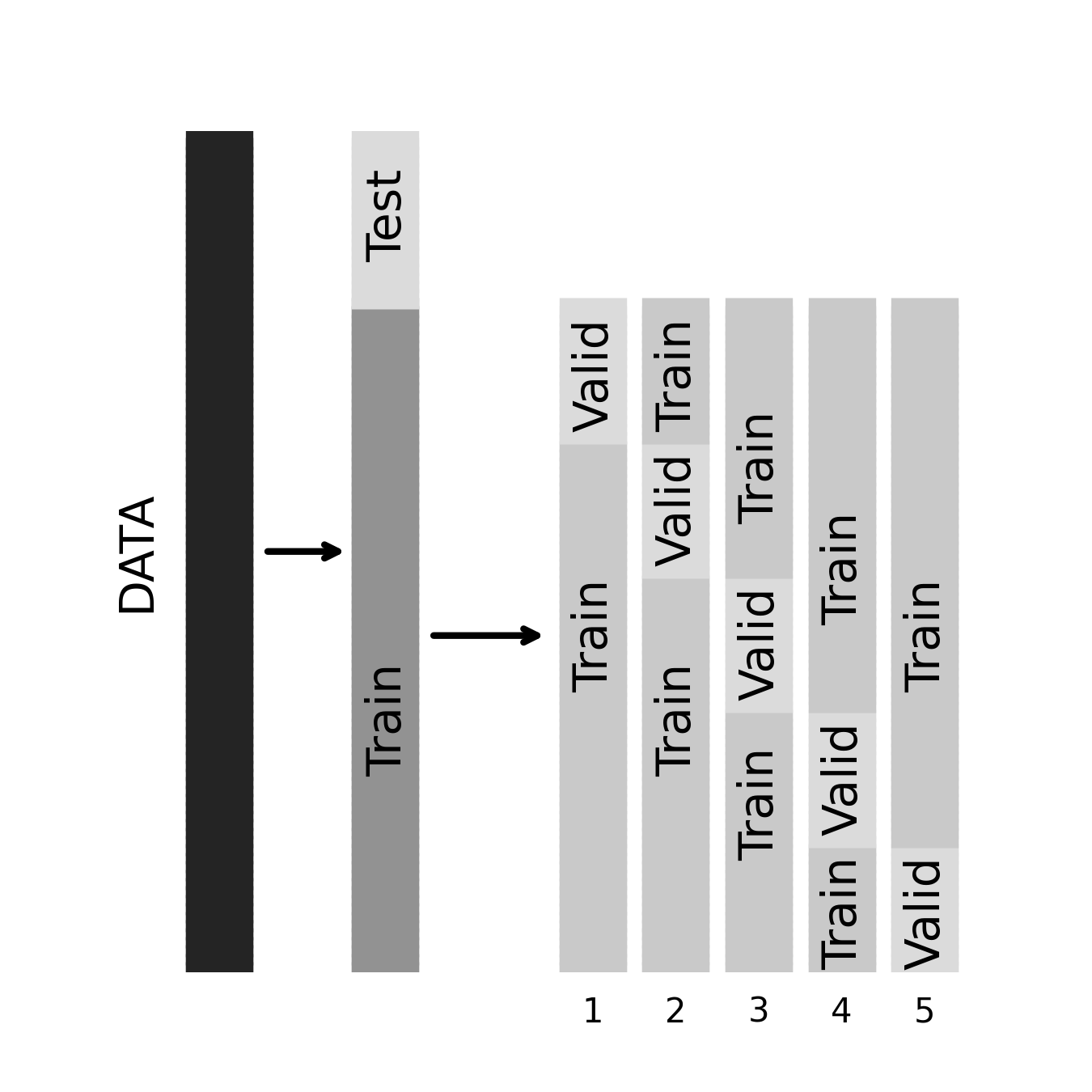
Cross-validation for model selection