Welcome to Psych 532!

David Donoho
- Statistician who has made fundamental contributions, including huge impact in application of “compressed sensing” in the geosciences.
- Together with other collaborators (Claerbout, Buckheit) also had impact in defining computational reproducibility. We’ll come back to that in a few weeks.
- The article starts with a critique of the ~2015 interest in “data science” within universities, and how it was constituted.
- Next, it walks through several milestones in the history of data science in the last 50 years.

John Tukey (1915-2000)
- Statistician. Probably one of the most influential scientists in the 20th century.
- Invented the Fast Fourier Transform.
- Invented the term (and methods of) Exploratory Data Analysis.

Leo Breiman (1928-2005)
- Statistician, who returned to academia after some time doing a variety of consulting.
- Developed important data analysis algorithms (random forests, bagging).
- “Statistical modeling: The two cultures”

The two cultures

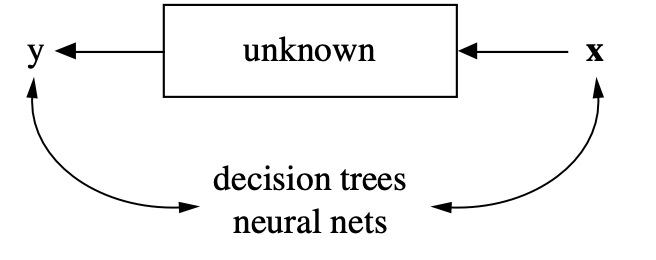
This idea had a huge influence. We’ll come back to it when we discuss machine learning in a few weeks.